
The diffusion-based text-to-image model harbors immense potential in transferring reference style. However, current encoder-based approaches significantly impair the text controllability of text-to-image models while transferring styles. In this paper, we introduce DEADiff to address this issue using the following two strategies: 1) a mechanism to decouple the style and semantics of reference images. The decoupled feature representations are first extracted by Q-Formers which are instructed by different text descriptions. Then they are injected into mutually exclusive subsets of cross-attention layers for better disentanglement. 2) A non-reconstructive learning method. The Q-Formers are trained using paired images rather than the identical target, in which the reference image and the ground-truth image are with the same style or semantics. We show that DEADiff attains the best visual stylization results and optimal balance between the text controllability inherent in the text-to-image model and style similarity to the reference image, as demonstrated both quantitatively and qualitatively.
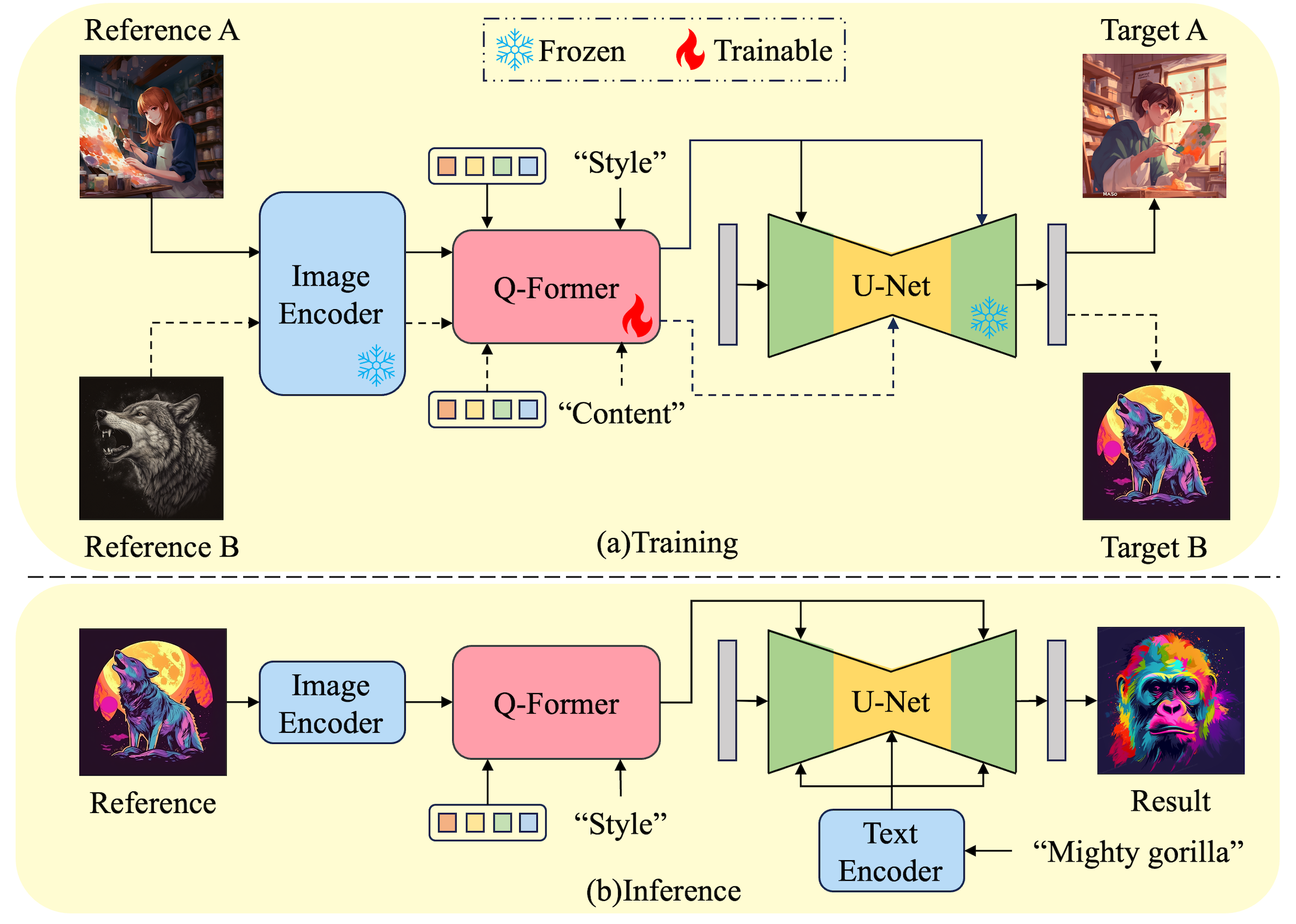
Core Idea: To remove the interference of semantics from the reference image, only extract its style-relevant features and inject them into the layers responsible for capturing style features in the diffusion U-Net.
Training Paradigm: Instruct the Q-Former on the condition of "style" and "content" to selectively extract corresponding features and inject them into mutually exclusive subsets of cross-attention layers for better disentanglement between semantics and styles. Our constructed training dataset with three distinct types of paired reference and target image is utilized to equip the Q-Former with the capability of disentangled representation extraction.
Inference Paradigm: Inject the output queries of the Q-Former with "style" conditions to fine layers of the diffusion U-Net, which respond to style information rather than global semantics.

Qualitatively: Given a reference image and a text prompt, DEADiff not only better adheres to the textual prompts but also significantly preserves the overall style and detailed textures of the reference image, with very minor differences in the color tones.
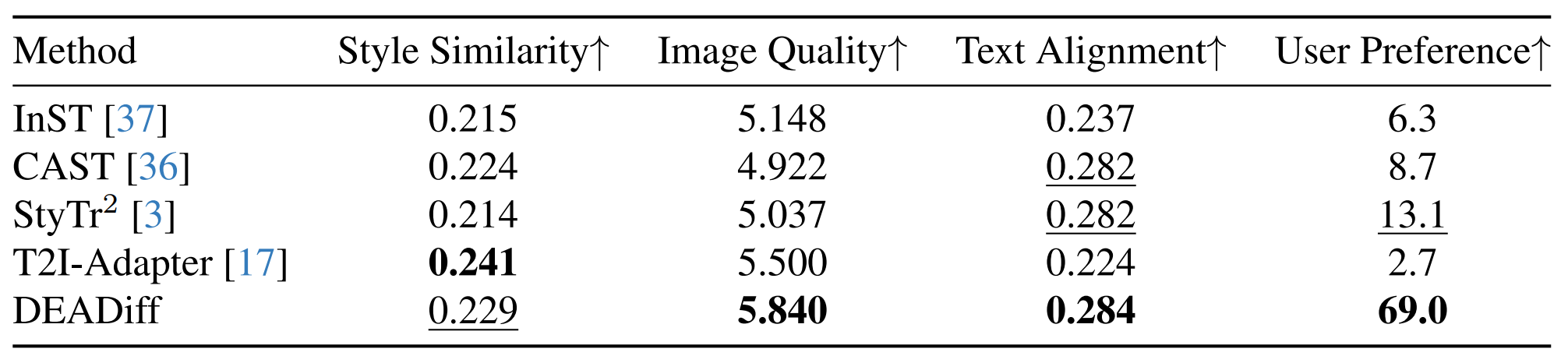
Quantitatively: DEADiff achieves an optimal balance between text fidelity and style similarity with the most pleasing image quality. Meanwhile, the big margin in user preference achieved by DEADiff further demonstrates its broad application prospects.


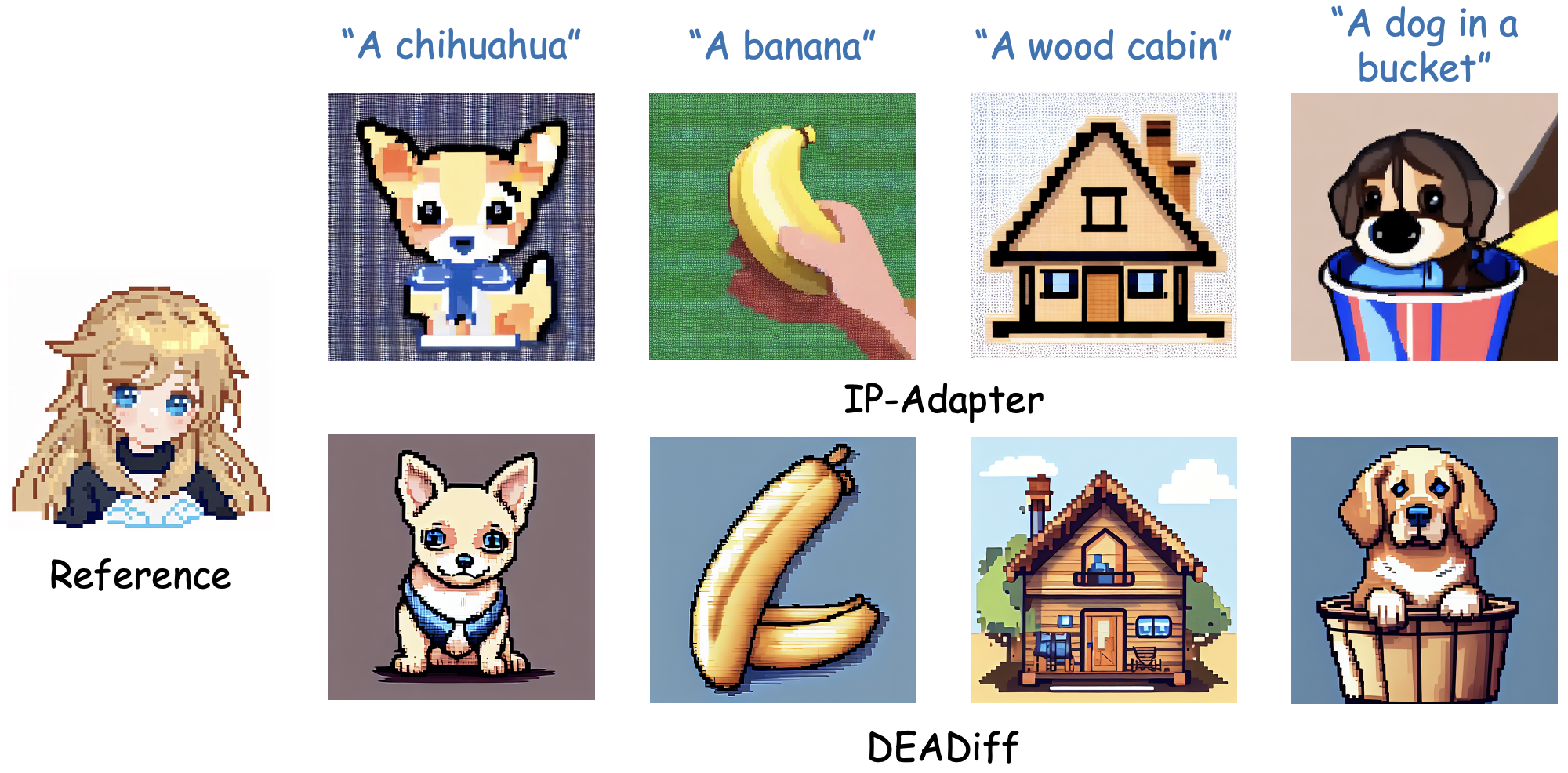






This is a novel application of DEADiff. Instructed by the "content" condition, DEADiff can extract the semantics of a reference image and achieve its stylization under the guidance of an extra text prompt.


